

Código 42, la compañía detrás de CrashPlan ha decidido abandonar por completo a los usuarios domésticos CrashPlan Shutters Copia de seguridad en la nube para usuarios domésticos CrashPlan Shutters Copia de seguridad en la nube para usuarios domésticos Code42, la compañía detrás de CrashPlan, ha anunciado que está abandonando usuarios domésticos. CrashPlan for Home está siendo eliminado, con Code42 en cambio enfocándose completamente en clientes empresariales y comerciales. Lee mas . Su precio súper competitivo convirtió su solución de respaldo en una tentación para las personas con grandes necesidades de respaldo. Si bien el hecho de que no cumplan sus promesas puede haber generado semillas de desconfianza, existen otros proveedores de servicios en la nube. ¿Pero en qué proveedor confías con tu archivo de memes?
Actualmente, el líder mundial en computación en la nube es Amazon Web Services (AWS). La curva de aprendizaje de AWS puede parecer abrupta, pero en realidad, es simple. Descubramos cómo aprovechar la plataforma en la nube líder mundial.
Solución de almacenamiento simple
La solución de almacenamiento simple, comúnmente conocida como S3, es la solución de almacenamiento de Amazon. Algunas compañías notables que usan S3 incluyen Tumblr, Netflix, SmugMug y, por supuesto, Amazon.com. Si su mandíbula aún está adherida a su rostro, AWS garantiza una durabilidad de 99.99999999999 por ciento para su opción estándar y un tamaño de archivo máximo (de cualquier archivo) de cinco terabytes (5 TB). S3 es un almacén de objetos, lo que significa que no está diseñado para instalar y ejecutar un sistema operativo, sino que está perfectamente diseñado para realizar copias de seguridad.
Los niveles y precios
Por mucho, esta es la parte más complicada de S3. El precio varía de una región a otra, y nuestro ejemplo utiliza los precios actuales para la región de los EE. UU. (Virginia del Norte). Eche un vistazo a esta tabla:

S3 se compone de cuatro clases de almacenamiento. Estándar obviamente es la opción estándar. En general, acceder a los datos con menor frecuencia es más barato para almacenar sus datos, pero es más costoso obtener y eliminar sus datos. Redundancia reducida generalmente se utiliza para los datos que puede regenerar si se pierde, como las miniaturas de imágenes, por ejemplo. Glacier se utiliza para el almacenamiento de archivos, ya que es el más barato para almacenar. Sin embargo, pasarán entre tres y cinco horas antes de que puedas recuperar un archivo de Glacier. Con glaciar o almacenamiento en frío, obtiene costos reducidos por gigabyte pero aumenta los costos de uso. Eso hace que el almacenamiento en frío sea más adecuado para el archivo y la recuperación de desastres. Las empresas generalmente aprovechan una combinación de todas las clases para reducir aún más los costos.
Lo mejor en cada categoría está marcado en azul. La durabilidad es lo poco probable que su archivo se pierda. Reducción de Redundancia Bar, Amazon tendrá que sufrir una pérdida catastrófica en dos centros de datos antes de que se pierdan sus datos. Básicamente, AWS almacenará sus datos en múltiples instalaciones con todas las clases excepto la clase de redundancia reducida. La disponibilidad es la improbabilidad de que haya tiempo de inactividad. El resto se demuestra más fácilmente por medio de un ejemplo.
Ejemplo de uso
Nuestro caso de uso es el siguiente.
Quiero almacenar diez archivos en S3 Standard con un tamaño total de un gigabyte (1 GB). Cargar los archivos o Put incurrirá en la solicitud con un costo de $ 0.005 y $ 0.039 para el almacenamiento total. Eso significa que en el primer mes se le cobrará un total de 4.5 centavos ($ 0.044) y poco menos de 4 centavos ($ 0.039) por estacionar sus datos a partir de entonces.
¿Por qué hay una estructura de precios tan complicada? Esto se debe a que es pago por lo que usted usa. Nunca pagas por algo que no usas. Si piensas en una empresa a gran escala, esto ofrece todas las ventajas de tener una solución de almacenamiento de clase mundial, manteniendo los costos al mínimo absoluto. Amazon también proporciona una calculadora mensual simple que puede encontrar aquí, para que pueda proyectar su gasto mensual. Afortunadamente, también ofrecen un nivel gratuito, que puede registrarse aquí, para que pueda probar sus servicios por hasta 12 meses. Al igual que con cualquier cosa nueva, una vez que comienzas a usarla, se vuelve más cómoda y comprensible.
La consola
El nivel gratuito de AWS le permite probar todos sus servicios, en cierta medida, durante todo un año. Dentro del nivel gratuito, S3 le ofrece 5 GB de almacenamiento, 20, 000 obtiene y 2, 000 puts. Esto debería permitir un amplio margen de maniobra para probar AWS y decidir si se ajusta a sus requisitos. El registro en AWS te lleva a través de unos pocos pasos. Necesitará una tarjeta de crédito o débito válida y un teléfono para fines de verificación. Una vez que inicie la consola de administración, será bienvenido al panel de AWS.
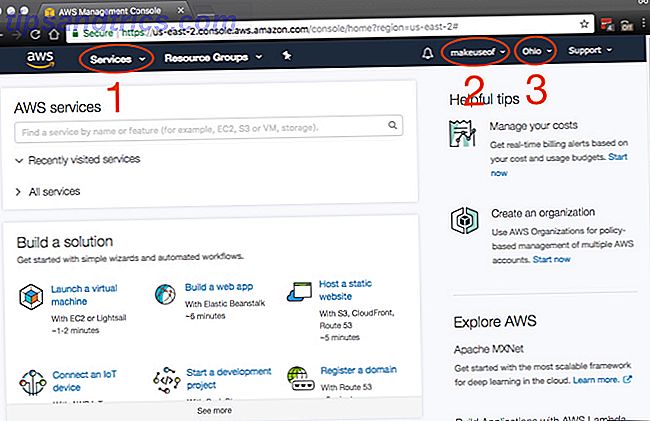
A simple vista, puede parecer que hay mucho que asimilar, y eso es simplemente porque sí lo hay. Los elementos principales a los que accederá, que están anotados en la captura de pantalla, son:
- Servicios: sorpresa, sorpresa, aquí es donde encontrará todos los servicios de AWS.
- Cuenta: para acceder a su perfil y facturación.
- Región: esta es la región de AWS en la que está trabajando.
Como desea la latencia más baja entre su (s) computadora (s) y AWS, elija una región que esté más cerca de usted. Hay algunas regiones que no tienen todos los servicios de AWS, pero sí se implementan de forma continua. ¡Afortunadamente para nosotros, S3 está disponible en todas las regiones!
S3 Seguridad
Antes de continuar, el primer trabajo es proteger su cuenta. Haga clic en Servicios> Seguridad, identidad y cumplimiento> IAM . En el proceso, también le otorgaremos los permisos necesarios a su computadora, para que pueda realizar copias de seguridad y restaurar de forma segura.
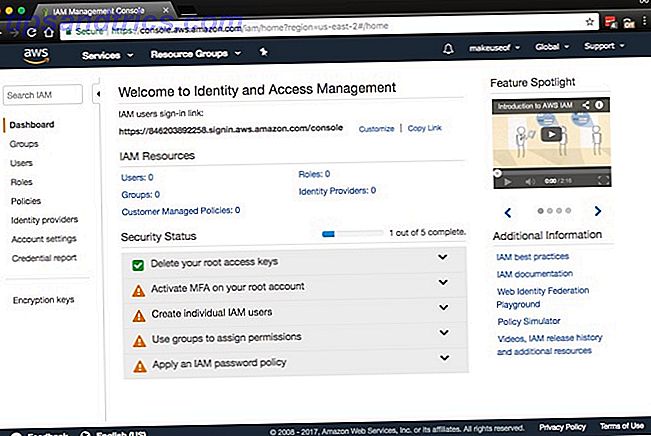
Este es un proceso simple de cinco pasos. Notará en la captura de pantalla que MFA se puede activar en su cuenta. Aunque autenticación multifactor (MFA), también conocida como autenticación de dos factores (2FA) Cómo asegurar Linux Ubuntu con autenticación de dos factores Cómo proteger Linux Ubuntu con autenticación de dos factores ¿Desea una capa adicional de seguridad en su inicio de sesión de Linux? Gracias a Google Authenticator, es posible agregar autenticación de dos factores a su PC Ubuntu (y otros sistemas operativos Linux). Leer más, no es obligatorio, es muy recomendable. En pocas palabras, requiere una combinación de su nombre de usuario y contraseña, junto con un código en su dispositivo móvil. Puede obtener un dispositivo MFA físico compatible o utilizar una aplicación como Google Authenticator. Dirígete a App Store o Play Store para descargar la aplicación Google Authenticator.
Uso de la autenticación de factor múltiple opcional
Expanda Active MFA en su cuenta raíz y haga clic en Administrar MFA . Asegúrese de que esté seleccionado un dispositivo MFA virtual y haga clic en Siguiente paso .
Abre Google Authenticator en tu dispositivo y escanea el código de barras que está en la pantalla. Escriba el código de autorización en el cuadro Código de autorización 1 y espere a que el código se actualice en Google Authenticator. El siguiente código se tarda aproximadamente 30 segundos en mostrarse. Escriba el nuevo código en el cuadro Código de autorización 2 de Google Authenticator. Ahora haga clic en el botón Activar Virtual MFA . Una vez que actualice su pantalla, Activar MFA tendrá el tic verde.

Ahora debería haber activado MFA en su cuenta y haber vinculado Google Authenticator a AWS. La próxima vez que inicie sesión en la Consola de AWS, ingresará su nombre de usuario y contraseña normalmente. AWS le solicitará un código de MFA. Esto se obtendrá de la aplicación Google Authenticator tal como lo hizo en el paso anterior.
Grupos y Permisos
Es hora de decidir el nivel de acceso que su computadora tendrá para AWS. La manera más fácil y segura de hacerlo será crear un grupo y un usuario para la computadora que desea respaldar. Luego conceda acceso o agregue un permiso para que ese grupo solo acceda a S3. Hay numerosas ventajas con este enfoque. Las credenciales otorgadas a dicho grupo están limitadas a S3 y no se pueden usar para acceder a ningún otro servicio de AWS. Además, en el desafortunado caso de que se hayan filtrado sus credenciales, solo necesita eliminar el acceso del grupo y su cuenta de AWS estará a salvo.
En realidad, tiene más sentido crear el grupo primero. Para hacerlo, expanda Crear usuarios individuales de IAM y haga clic en Administrar usuarios . Haga clic en Grupos en el panel de la izquierda y luego en Crear nuevo grupo . Elija un nombre para su grupo y haga clic en Siguiente paso . Ahora vamos a adjuntar el permiso o la política para este grupo. Como solo desea que este grupo tenga acceso a S3, filtre la lista escribiendo S3 en el filtro. Asegúrese de que AmazonS3FullAccess esté seleccionado y haga clic en Siguiente paso seguido de Crear grupo .

Crear un usuario
Todo lo que necesita hacer ahora es crear un usuario y agregarlo al grupo que creó. Seleccione Usuarios en el panel de la izquierda y haga clic en Agregar usuario . Elija el nombre de usuario que desee, en el tipo de acceso, asegúrese de que esté seleccionado el acceso programático y haga clic en Siguiente: Permisos . En la página siguiente, seleccione el grupo que creó y haga clic en Siguiente: Revisar . AWS confirmará que está agregando este usuario al grupo seleccionado y confirmará los permisos otorgados. Haga clic en Crear usuario para pasar a la siguiente página.
Ahora verá una ID de clave de acceso y una clave de acceso secreta . Estos son autogenerados y solo se muestran una vez. Puede copiarlos y pegarlos en una ubicación segura o hacer clic en Descargar .csv, que descargará una hoja de cálculo que contiene estos detalles. Esto es el equivalente al nombre de usuario y la contraseña que su computadora utilizará para acceder a S3.
Vale la pena señalar que debe tratar estos con el más alto nivel de seguridad. Si pierde su clave de acceso secreta, no hay forma de recuperarla. Tendrá que volver a la consola de AWS y generar una nueva.

Tu primer cubo
Ha llegado el momento de crear un lugar para sus datos. S3 tiene tiendas llamadas cubos. Cada nombre de cubo debe ser globalmente único, lo que significa que cuando crees un cubo serás el único en el planeta con ese nombre de cubo. Cada segmento puede tener su propio conjunto de reglas de configuración establecidas en su contra. Puede habilitar el control de versiones en los depósitos para que conserve copias de los archivos que actualice, de modo que pueda volver a las versiones anteriores de los archivos. También hay opciones para la replicación entre regiones para que pueda realizar una copia de seguridad de sus datos en otra región de otro país.
Puede llegar a S3 navegando a Servicios> Almacenamiento> S3 . Crear un segmento es tan fácil como hacer clic en el botón Crear segmento . Después de haber elegido un nombre global único (minúsculas solamente), seleccione una región en la que desea que su cubo viva. Al hacer clic en el botón Crear finalmente obtendrá su primer segmento.

La línea de comando es vida
Si la línea de comando es tu arma de elección 4 formas de enseñarte comandos de terminal en Linux 4 maneras de enseñarte comandos de terminal en Linux Si quieres convertirte en un verdadero maestro de Linux, tener un poco de conocimiento del terminal es una buena idea. Aquí puedes usar métodos para comenzar a enseñarte a ti mismo. Lea más, puede acceder a su cubo S3 recién creado utilizando s3cmd, que puede descargar desde aquí. Después de haber elegido la última versión, descargue el archivo zip en la carpeta que elija. La última versión actual es 2.0.0 que usará en nuestro ejemplo. Para descomprimir e instalar s3cmd abra una ventana de terminal y escriba:
sudo apt install python-setuptools unzip s3cmd-2.0.0 cd s3cmd-2.0.0 sudo python setup.py install s3cmd ahora está instalado en su sistema y está listo para ser configurado y vinculado a su cuenta de AWS. Asegúrese de tener a mano su ID de clave de acceso y la clave de acceso secreto cuando creó su usuario. Comience escribiendo
s3cmd --configure Se te pedirá que ingreses algunos detalles. En primer lugar, se le promocionará para que ingrese su ID de clave de acceso seguido de su clave de acceso secreta. Todas las demás configuraciones se pueden dejar como predeterminadas con solo presionar la tecla Intro, excepto la configuración de Encriptación . Puede elegir una contraseña aquí para que los datos enviados y salidos de S3 estén encriptados. Esto evitará que un hombre en el medio ataque Cinco herramientas de cifrado en línea para proteger su privacidad Cinco herramientas de cifrado en línea para proteger su privacidad Lea más, o alguien que intercepte su tráfico de Internet.
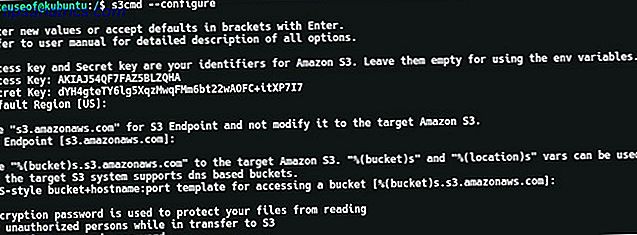
Al final del proceso de configuración, s3cmd realizará una prueba para asegurarse de que todas las configuraciones estén funcionando y de que pueda conectarse con éxito a su cuenta de AWS. Cuando esto esté hecho, podrá escribir algunos comandos como:
s3cmd ls Esto mostrará una lista de todos los segmentos dentro de su cuenta S3. Como muestra la siguiente captura de pantalla, ¡el cubo que creó está visible!

Sincronización con línea de comandos
El comando de sincronización para s3cmd es extremadamente versátil. Es muy similar a la forma en que normalmente se copia un archivo en Linux, y se ve algo así como esto:
s3cmd sync [LOCAL PATH] [REMOTE PATH] [PARAMETERS] Prueba su uso con una simple sincronización. Primero, cree dos archivos de texto usando el comando táctil, luego use el comando de sincronización para enviar los archivos que acaba de crear al cubo creado anteriormente. Actualiza el cubo S3; ¡notarás que los archivos han sido enviados a S3! Asegúrese de reemplazar la ruta local con la ruta local en su computadora, así como cambiar la ruta remota a su nombre de depósito. Para lograr este tipo:
touch file-1.txt touch file-2.txt s3cmd sync ~/Backup s3://makeuseof-backup 
El comando de sincronización, como se mencionó, primero verifica y compara ambos directorios. Si un archivo no existe en S3, lo cargará. Más aún, si existe un archivo, se comprobará si se ha actualizado antes de copiar a S3. Si también desea eliminar los archivos que ha eliminado localmente, puede ejecutar el comando con el parámetro -delete-removed . Pruebe esto borrando primero uno de los archivos de texto que hemos creado seguido por el comando de sincronización con el parámetro adicional. Si luego actualiza su cubo S3, ¡el archivo eliminado ya ha sido eliminado de S3! Para probar esto, escribe:
rm file-1.txt s3cmd sync ~/Backup s3://makeuseof-backup --delete-removed 
A simple vista, puede ver cuán convincente es este método. Si desea realizar una copia de seguridad de algo en su cuenta de AWS, puede agregar el comando de sincronización a un trabajo cron. Cómo programar tareas en Linux con Cron y Crontab Cómo programar tareas en Linux con Cron y Crontab La capacidad de automatizar tareas es una de ellas tecnologías futuristas que ya están aquí. Todos los usuarios de Linux pueden beneficiarse del sistema de programación y las tareas de los usuarios, gracias a cron, un servicio en segundo plano fácil de usar. Lea más y vuelva a encender su computadora automáticamente a S3.
La alternativa GUI
Si la línea de comando no es lo tuyo, existe una alternativa de interfaz gráfica de usuario (GUI) a s3cmd: Cloud Explorer. Si bien no tiene una interfaz muy moderna, tiene algunas características interesantes. Irónicamente, el método más fácil para tener en sus manos la última versión es a través de la línea de comando. Una vez que haya abierto una ventana de terminal con una carpeta en la que desea instalarla, escriba:
sudo apt -y install How to Use APT and Say Goodbye to APT-GET in Debian and Ubuntu How to Use APT and Say Goodbye to APT-GET in Debian and Ubuntu Linux is in a state of permanent evolution; major changes are sometimes easily missed. While some enhancements can be surprising, some simply make sense: check out these apt-get changes and see what you think. Read More openjdk-8-headless ant git git clone https://github.com/rusher81572/cloudExplorer.git cd cloudExplorer ant cd dist java -jar CloudExplorer.jar Cuando se inicia la interfaz, algunos de los campos obligatorios ya deberían ser familiares. Para cargar su cuenta de AWS, ingrese su clave de acceso, clave secreta, ingrese un nombre para su cuenta y haga clic en Guardar .
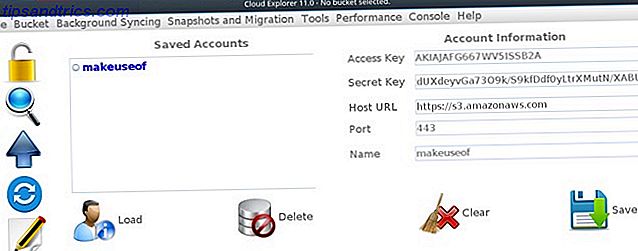
Ahora puede hacer clic en su perfil guardado y obtener acceso a su depósito.
Explorando el Explorer
Echando un vistazo rápido a la interfaz, verá lo siguiente:
- Cerrar sesión
- Explora y busca
- Subir archivos
- Sincronización
- Editor de texto
- Un panel para una lista de tus cubos
- Un panel para navegar un cubo seleccionado
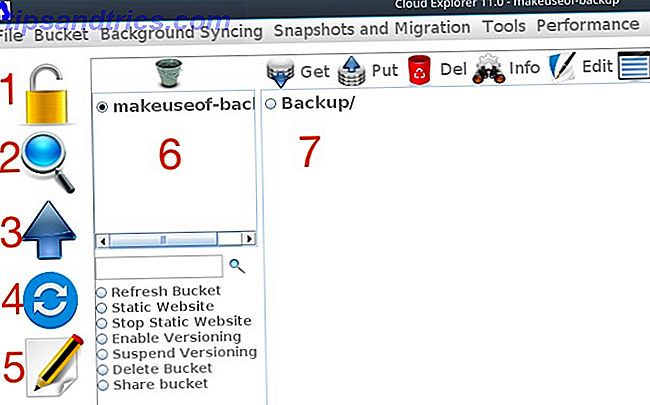
La configuración de las capacidades de sincronización de Cloud Explorer es similar a s3cmd. En primer lugar, cree un archivo que no exista dentro del depósito S3. A continuación, haga clic en el botón Sincronizar en Cloud Explorer y busque la carpeta que desea sincronizar con S3. Al hacer clic en A S3 verificará las diferencias entre la carpeta en su computadora local y la carpeta con S3 y cargará cualquier diferencia que encuentre.
Cuando actualice el depósito S3 en el navegador, notará que el nuevo archivo se ha enviado a S3. Desafortunadamente, la función de sincronización de Cloud Explorer no admite los archivos que haya eliminado en su máquina local. Entonces, si elimina un archivo localmente, aún permanecerá en S3. Esto es algo a tener en cuenta.

Los usuarios domésticos pueden usar almacenamiento en la nube enfocado en el negocio
Si bien AWS es una solución diseñada para que las empresas aprovechen la nube, no hay ninguna razón para que los usuarios domésticos no participen en la acción. El uso de la plataforma en la nube líder mundial viene con muchos beneficios. Nunca tendrá que preocuparse por actualizar el hardware o pagar por cualquier cosa que no use. Otro hecho interesante es que AWS tiene más participación de mercado que los siguientes 10 proveedores combinados. Esto es una indicación de qué tan avanzados están. La configuración de AWS como una solución de respaldo requiere:
- Creando una cuenta.
- Asegurando su cuenta con MFA.
- Creando un grupo y asignando permisos al grupo.
- Agregar un usuario al grupo.
- Creando tu primer cubo.
- Usar la línea de comando para sincronizar con S3.
- Una alternativa GUI para S3.
¿Actualmente usas AWS para algo? ¿Qué proveedor de copia de seguridad en la nube usa actualmente? ¿Qué características busca al elegir un proveedor de respaldo? Háganos saber en los comentarios a continuación!